Testing with Kettle
Scenario
In the last few months I have been developing the second main release of a java desktop application that performs some data manipulation using kettle engine. It features a lightweight gui that basically launches jobs and pass variables, plus a few maintenance and utility tasks. When I wrote the first release I completely skipped the testing issue: the wrapping code was quite straightforward, and the transformations can be tested live using a carte istance on a production-like server. Nonetheless, after roll-out I have endured a fair amount of bug fixing. Most of them could have been avoided with a more elaborated testing system.
Furthermore, starting the development of a second main release, I realized very soon that code breaking was all too likely. I decided then to introduce some automation at transformation level using kind of tdd approach with this key points in mind:
- Build a robust set of automated tests executable during building phase
- Tests should be executed both in an isolated fashion and as suite
- A report should be generated summing up the total number of tests, showing which one failed, like junit usually does
- The failure of a single test should not block the following tests. It should prevent building, though.
- Tests must be part of a maven building cycle, being this the tool of choice to support the development of this application
As a side note, Intellij IDEA is the companion IDE for this software: transformations and jobs are designed with Spoon, the pdi gui. All the rest is managed by the IDE.
Of course, this is not a typical ETL scenario: there isn’t any data warehouse to be built and maintained, any change data capture strategy or slowly-change dimension to accomodate. However, the kind of tasks to accomplish were similar up to a point: setting connections, firing select statement to legacy db, transforming data according to business rules, presenting distilled data to a third-party application.
I think that I still haven’t got to the ending point of this approach but something is already clear and I would like to share it.
Testing in etl context
A note to be thought about is that the concept of unit testing in an ETL environment is quite disguising. According to a general accepted mindset, unit tests happen at a very low level in software development. Typically a class method is something to write test about. Provided a well-written class (single responsability, design patterns, dependency injections and the likes) unit tests allow isolated checks.
In ETL, on the contrary, you deal with complex transformations that manipulate an input data set to get an output. We are normally far above one single class abstraction level. In Pentaho Data Integration a transformation is an ordered sequence of steps, each affecting the stream of data in a specific way. From an internal point of view, a step is composed by a few classes, so the steps are the proper subjects for a unit test approach and actually these tests are run when you build pdi from source. No need for them in a solution development, then.
In pentaho forums and within the community, the test topic has been risen several times. There are already a lot of great ideas coming from blog posts and there is also a very promising approach consisting of building test dataset right into Spoon gui. Here a few references (apologize if i am missing someone):
- Kettle Data Sets (Matt Casters)
- Kettle Test Framework (Diethard Steiner)
- Pentaho Kettle Testing (Dan Moore)
- ETL Testing with Pentaho Data Integration (Matthew Carter)
All this ideas and projects converge to a same point: transformation test requires a black box method. In other words you should write a golden data set, i.e. the data you would get as the output of a trans, and the input data sets. Each test is successful if the output is equal to the golden one. So, at some point you should decorate your original transformation with a comparison.
I followed this approach, too.
What is in a test?
Whatever the thing to test or the used framework, writing a test always involved a setup of some fixtures, test execution, cleaning up. In other words you put the system in a known state, execute the code, get the result (success or failure), clean up (tear down) the state. Pdi provides the user with all the tools needed to write a job that acts as a test runner. From a functional point of view, you will have five kinds of entries:
- entries to create the storage medium needed: either database tables or files
- entries to populate the storage: here you upload both the input data and the golden data
- the transformation to be tested
- transformations that compare golden and output data
- entries to clean temp files or tables
An example of runner can be:
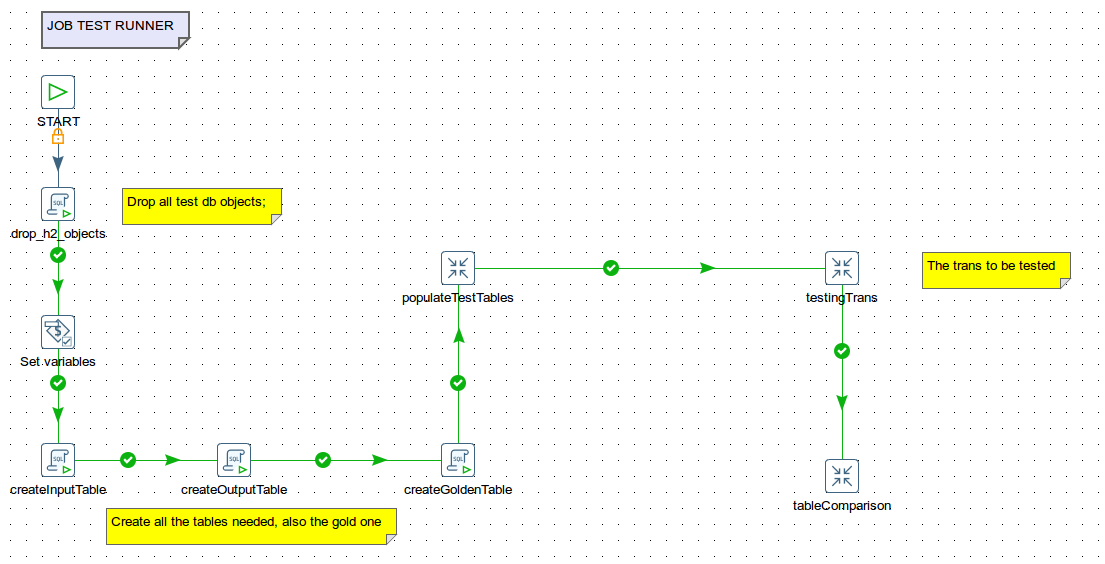
Tables and connections
In a typical scenario you have two kinds of tables: source and target. The problem lays on the fact that you normally don’t develop etl in a production-like environment. So you won’t probably have a source and a target database exactly equal to what your solution will deal with in prod.
You may think that there is no need to stretch the tests up to this point. For instance, using the concept of result as in copy-rows-to-result step, you can pass rows from a trans to another. So, you can avoid write a test to fire queries to a db and only check what happens in the middle: in fact you would test only the T in ETL.
In my opinion, however, testing queries can be valuable to better understand what you want, as often happens in a test-driven-development (tdd) approach. Furthermore it encourages you to put sql scripts under version control and keep them in sync with test code.
But how you can mimic a database? And how you can standardize a test process as part of a build when you have many developers working on the same project? The answer is simple-jndi. It is a small library that allows database abstraction, so that you can use a connection only passing its name around within an application. Pdi supports natively simple-jndi: you just have to define connection properties in the simple-jndi/jdbc.properties file.
Now, the real catch is create a connection jndi name at runtime in order to switch from a test to a prod environment:
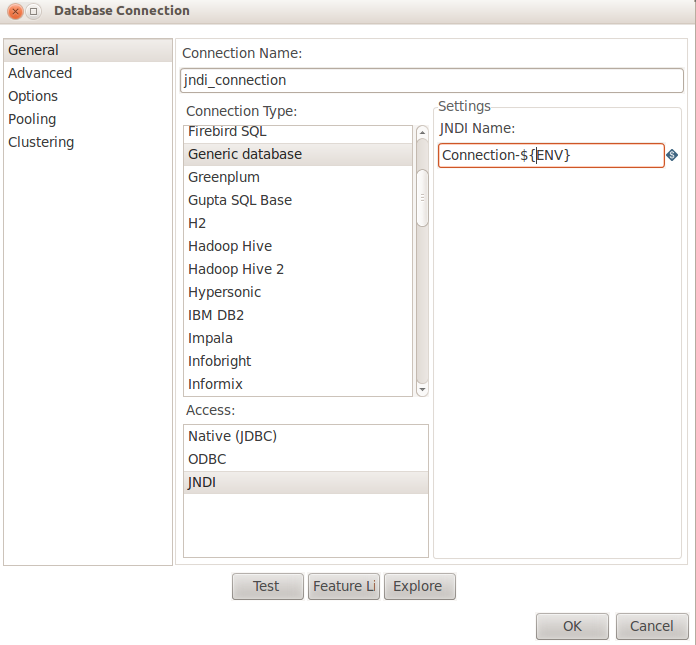
Now the actual jndi name can be set with the help of a kettle variable, so you can change it according to the relevant environment. Coupled with the jdbc.properties you have the first brick to build a test runner for sql queries. Here is an example of this file content.
# Production legacy db
Connection-PROD/type=javax.sql.DataSource
Connection-PROD/driver=com.informix.jdbc.IfxDriver
Connection-PROD/url=jdbc:informix-sqli://10.10.10.10:1526/db:INFORMIXSERVER=server
Connection-PROD/user=
Connection-PROD/password=
# Testing legacy db
Connection-TEST/type=javax.sql.DataSource
Connection-TEST/driver=org.h2.Driver
Connection-TEST/url=jdbc:h2:~/testDatabse;MVCC=TRUE;MV_STORE=FALSE;AUTO_SERVER=TRUE;ALIAS_COLUMN_NAME=TRUE
Connection-TEST/user=
Connection-TEST/password=
Comparison
Compare two streams (an output and a golden one, in our case) is really easy with kettle. For text files the merge rows step (diff) will be the core of your transformation. Followed by a filter rows that let only pass non-identical rows, it can act as an assert clause and cause an Abort that signals the failure of the test.
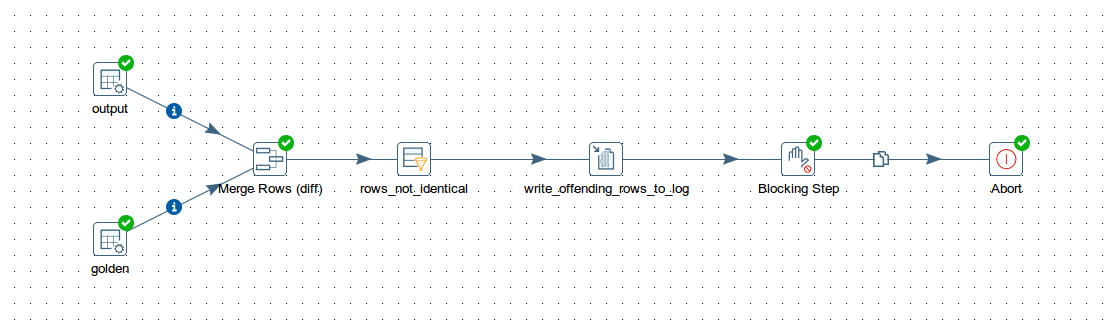
In the transformation shown above, a write-to-log step will give evidence of the offending rows. Once all the failing rows have been written to the log, the Abort step is activated causing an exception and suspending execution. Please note that the merge rows step requires a previous sorting on the keys. Also, consider that part of this transformation can conveniently be moved to a mapped subtrans to avoid repetitions.
For tables the solution is even easier with the table compare step

This step is highly configurable: the names of the tables and the key fields to match can be defined at runtime as variables/named parameters. As a consequence you only need to build this trans once and then use it in as many test jobs as you want changing the parameters values passed through the transformation job entry. The step outputs the offending rows to the error handle buffer and provides information about keys and fields that do not match.
The suite runner
Ideally you will have a runner job for each test, with all the relevant files organized in a filesystem folder. Here you have the .kjb file, the data textfiles, transformations that you need just for that test. Clearly you don’t want to move or copy the trans to be tested: it must stay in its original position and referred to using variables.
Once you have multiple tests, you need a way to launch them all, with some flexibility. Again, this can be done right in kettle, using an outer job, and with a bit of effort you can minimize the code to wrote using a single job entry with “execute for every input row” flagged in the Advanced tag.
However I have explored another way via kettle API, that I found more suitable in my specific case (see the key points above).
In order to launch a job via java code, as you can easily found out by googling, you need to instantiate a KettleEnvironment, create a JobMeta object passing it a file, and then create a Job.
As you need only one KettleEnvironment for all tests, a convenient solution is a singleton instantiated when the test phase of your application build starts. Something along the lines
import org.pentaho.di.core.KettleEnvironment;
import org.pentaho.di.core.exception.KettleException;
import org.pentaho.di.core.exception.KettleXMLException;
import org.pentaho.di.job.Job;
import org.pentaho.di.job.JobMeta;
import java.util.HashMap;
import java.util.Map;
public enum KettleTestEnvironment {
INSTANCE;
private KettleTestEnvironment() {
try {
KettleEnvironment.init();
} catch (KettleException e) {
e.printStackTrace();
}
}
The above Enum can also expose methods to execute jobs, like in this snippet:
public void runKettleJob(String jobPath){
Map<String,String> jobVariables = getStandardTestJobVariables();
executeJob(jobPath,jobVariables);
}
private void executeJob(String jobTestFolder, Map<String,String> jobVariables){
try {
String jobPath = TEST_REPOSITORY_FOLDER + "/" + jobTestFolder + "/" + JOB_TEST_RUNNER_FILENAME;
JobMeta jobMeta = new JobMeta(jobPath,null);
Job job = new Job(null, jobMeta);
for (Map.Entry<String,String> variable : jobVariables.entrySet()){
job.setVariable(variable.getKey(),variable.getValue());
}
job.start();
job.waitUntilFinished();
if (job.getErrors() != 0) {
throw new RuntimeException("Error in transformations tests");
}
} catch (KettleXMLException e) {
e.printStackTrace();
throw new RuntimeException();
}
}
Now, you can create a base class to be extended by actual test classes, just to provide common functionalities like:
public abstract class KettleBaseTest {
protected static final KettleTestEnvironment kettleTestEnvironment = KettleTestEnvironment.INSTANCE ;
@Rule
public TestRule watcher = new TestWatcher() {
protected void starting(Description description) {
System.out.println("Starting test: " + description.getMethodName());
}
protected void succeeded(Description description) {
System.out.println("Succeeded test: " + description.getMethodName());
}
};
}
This abstract class contains a reference to the kettle environment, and will make it available to subclasses. Furthermore, it provides a few AOP methods,
thanks to junit @Rule annotation, that basically output informative messages to the console when the tests are executed.
Now, a concrete test class can be written as:
public class PreparePeopleInFancySuitsTable extends KettleBaseTest{
@Test
public void prepareAvengersTable(){
String jobTestFolder = "prepare_avengers_table";
kettleTestEnvironment.runKettleJob(jobTestFolder);
}
@Test
public void prepareXMenTable(){
String jobTestFolder = "prepare_xmen_table";
kettleTestEnvironment.runKettleJob(jobTestFolder);
}
Now, you have junit tests that can be run via IDE in a very straightforward manner. You can run all tests in a shot, or a single class or a single method. In Intellij, but also in Eclipse for what I remember, junit support is very strong. And also maven integration is quite comfortable: if your test classes are in the standard folder, the surefire plugin will pick up your kettle tests along the other ones and incorporate their execution in the build cycle. A failing test will prevent a successful build but not a complete test execution.
As an additional consideration, you can also set a specific KETTLE_HOME and a KETTLE_JNDI_ROOT in your maven pom.xml, so that the surefire plugin will use them when run the test with the above mentioned
KettleEnivronment
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<systemPropertyVariables>
<KETTLE_HOME>${KETTLE_HOME}</KETTLE_HOME>
<KETTLE_JNDI_ROOT>${KETTLE_JNDI_ROOT}</KETTLE_JNDI_ROOT>
</systemPropertyVariables>
</configuration>
</plugin>
Finally, in Intellij maven settings you can arrange for passing properties from surfire to junit and have a consistent behaviour.
That’s all for the moment. I hope this can be useful for other developers interested in Pentaho Data Integration flexible and powerful engine.
blog comments powered by Disqus